It is common knowledge that Vivado uses an analytical place and route engine for better and more predictable design closure. As a result, Vivado got rid of the "cost table" (also commonly known as random seeds) user options.
What may be less well-known is that designers still have ways to introduce randomness into Vivado placement. Like the random seeds, this achieves different performance results. We have first-hand accounts from multiple customers relating how they got 10s of nanoseconds of WNS fluctuations, by simply making minute tweaks that do not affect the functionality at all. Unfortunately, these fluctuations can go either way, reminiscent of the effects of cost tables or placement seeds.
We have incorporated this behaviour into a feature on InTime.
How to run "random seeds" with InTime 1.6
Without talking too much Chaos Theory and butterflies flapping their wings from across the ocean, this approach is not a hack but a method to subtly introduce various stimuli. The intention is for Vivado to attempt different calculations and end up with different (and potentially better!) results for the otherwise unmodified design.
InTime's implementation requires that your design be routed beforehand, and it has to contain false timing paths. *From InTime 2.0 onwards, this requirement is no longer necessary. Here is how to use the new Placement Exploration recipe for Vivado:
- Open your routed project or DCP in InTime
- From the recipes dropdown, click and select the Placement Exploration recipe.

- Specify the number of different results you want in the "Runs per Round" flow property (10 in this example).

- Click "Start Recipe" to start running.
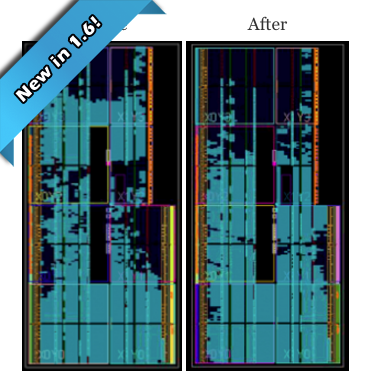
The following images show the chip view of the implemented design, before and after the Placement Exploration:
| Before | After |
 |
 |
Noticeable placement differences
prior to (left) and after (right) running Placement Exploration.
We query one of the affected cells via:
get_property LOC [get_cells mgtEngine/no_chipscope.gt3_rxuserrdy_r_reg].
Before running the recipe, the cell above was at SLICE_X52Y100. After the placement was stimulated, this cell shifted to SLICE_X38Y126. More importantly, the TNS improved by 78ns -- without changing the design at all. As randomness is involved, not all results generated via the new Placement Exploration recipe will be good. This is a painless approach with no impact on functionality. Read more about it in Application Note of Placement Exploration recipe.
Evaluation
If you are interested in trying this feature, sign up here to get a free evaluation.
Related Post: How Much Do You Really Know About Placement Seed Sweep?
This reminds me of all the 1-20 seed runs you made me to to find one that meets timing ! ^_^
January 11, 2017 at 5:47 pmGood times!
January 12, 2017 at 1:22 amI’m glad timing closure is more predictable now but desperate times called for desperate measures 😉
Great feature – looking forward to try it. I’ve made the same observation where small changes (even stepping a version generic) results in big TNS differences.
What I like most about this feature is that the recipe takes a post routed design as input instead of a post synth checkpoint. This hopefully means you can get a number of different placements at a fraction of the runtime compared to what “seeds” gave you in the past where it had to do a map & par for each “seed”?
Would be interesting to compare the runtimes of one strategy from this recipe to the full runtime of the design.
February 2, 2017 at 2:25 amThanks for your comments!
February 22, 2017 at 7:34 amYes, runtimes for different placements should be much shorter than in the past as they run incrementally. Hopefully this new recipe will be useful for your designs.